How I Read My Own Genome Over a Weekend

That 23andMe file has been sitting on my drive since 2019.
I’d paid $99, gotten a polished consumer interface, and walked away with almost nothing useful on the health side. The one genuinely interesting detail: a distant cousin who turned out to be another tech guy at Microsoft in Seattle. We probably shared 0.3% of our DNA and had never crossed paths. The internet works as intended.
Everything medical is heavily constrained by the FDA. The outputs land at the level of “slightly elevated Alzheimer’s risk” and “asparagus smell perception.” Those restrictions haven’t loosened since. So the file sat there, doing nothing, for five years.
A friend eventually pointed out the obvious: I was sitting on 600,000 data points and had done exactly nothing with them.
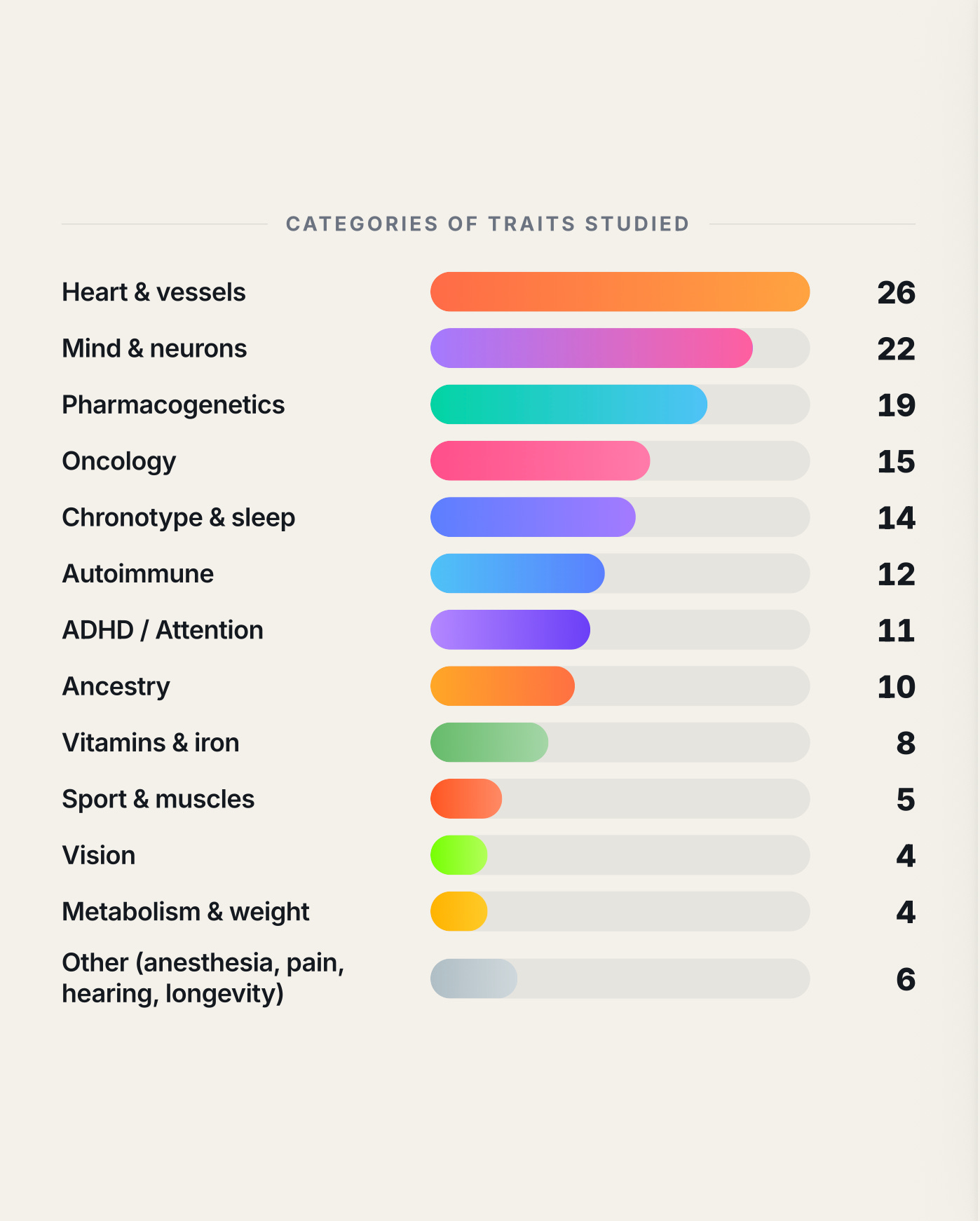
The raw 23andMe file isn’t a summary. It’s a dense text file full of SNPs: Single Nucleotide Polymorphisms, which sounds like a graduate seminar topic but just means: tiny places in your DNA where you differ from other people. One letter changed out of three billion. Multiply that by 600,000 and you have a surprisingly complete map of your biological quirks.
Used right, those SNPs tell you about disease predisposition, metabolic patterns, drug response, ancestry and ancient population origins, even distant connections to known historical lineages. The data was always there, but I never got to it.
Doing this properly used to require real bioinformatics fluency: Plink, VCF files, genome assembly builds, bash scripts, a stack of reference databases. Weeks of learning before any real output. Not impossible, but enough friction that almost nobody outside a research lab was doing it for themselves.
So I opened Claude Code in the terminal and typed one line:
“Here’s my 23andMe file. Check hereditary disease risk, pharmacogenetics, and parse nutrition and metabolism notes.”
That was it.
Claude identified what was needed, pulled the right tools and databases on its own, and built the pipeline. I didn’t write a single bash script. I didn’t configure a genome build. I didn’t spend three days reading documentation for a tool I’d use once.
The databases it pulled in:
ClinVar - hereditary disease variants
PharmGKB / CPIC - drug compatibility and metabolism
GWAS Catalog - risk associations for diabetes, heart disease, and other conditions
1000 Genomes - comparison against modern global populations
Ancient DNA databases - tracing ancestry against ancient peoples and migration paths
By the end of the weekend I had a personal report I can re-run anytime, no third-party service, no subscription, nothing leaving my machine. I saved a section of it for my doctor to put in the chart.



What I actually found:
Specific drug metabolism patterns: the pharmacogenetics piece turned out to be the most immediately practical. Some people process certain compounds fast, some slow, some atypically. I fall outside the standard range on a few things that are worth flagging before any new prescription gets written.
Elevated risk on a few conditions. I’m not listing them here both because it’s personal and because the framing matters a lot. Genetic risk is probabilistic. A raised number isn’t a diagnosis, it’s a signal to pay attention to a particular area. There’s a big difference.
Ancient Eastern European and Slavic lineages running deep. The ancestry section cross-referenced against ancient DNA migration patterns and placed my ancestors in specific regions across thousands of years. That part was more quietly fascinating than actionable, but seeing where your people were 4,000 years ago is one of those moments that’s hard to describe.
Variants affecting tolerance to certain medications - distinct from the metabolism patterns, but related. The kind of thing that’s genuinely useful to have documented somewhere.
My honest take: genetics isn’t a verdict.
Most SNPs only give probabilities. They aren’t diagnoses, they aren’t certainties, and without a sober reading of what the numbers actually mean, it’s very easy to spiral into anxiety over nothing. I’d recommend going in with that framing locked in, or doing it alongside someone: a doctor, a friend with a biology background who can help you contextualize what comes back.
That said, I found the whole thing genuinely valuable, the information actually exists now, in a form I control, that I can hand to a doctor and have it mean something.
Without Claude Code I’d have burned weeks just on tooling, probably given up, and the file would still be sitting there.
With it, the whole thing came together over two weekends.
I’m now looking for a lab to do a full genome sequence. 23andMe only covers a small fragment, around 0.02% of your actual genome. The rest is inference and approximation. Full sequencing gives you the complete picture, and the cost has dropped far enough that it’s no longer an exotic expense.
When that file comes back, Claude Code is the first thing I’m opening.